
MMLAB: Machine Learning Compute Cluster

SHORT SUMMARY
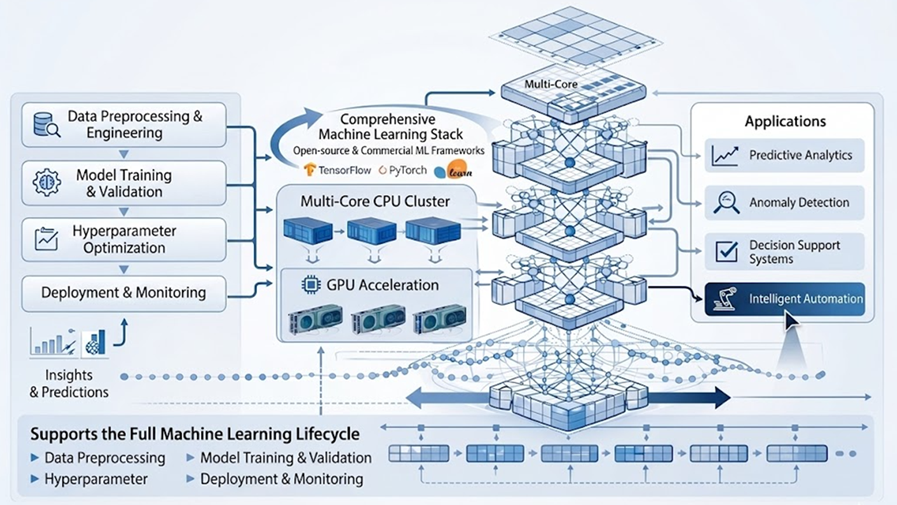
The MLLAB Machine Learning Compute Cluster provides a comprehensive, high-performance computational environment designed to support the full machine learning lifecycle, from data preprocessing and feature engineering through model training, validation, hyperparameter optimization, and production-ready deployment. Built on a robust multi-core CPU cluster infrastructure complemented by GPU acceleration, and equipped with a broad suite of open-source and commercial machine learning frameworks and libraries, this testbed enables researchers and industry partners to develop, benchmark, and deploy classical and modern machine learning models at scale.
Machine learning forms the computational backbone of modern Artificial Intelligence, powering predictive analytics, anomaly detection, decision support systems, and intelligent automation across virtually every industry sector. By providing accessible, scalable, and reproducible machine learning infrastructure, MLLAB supports the CITADELS Framework’s mission of democratizing DeepTech capabilities and enabling Industry 5.0 applications centered on human-centric automation, sustainable operations, and data-driven decision-making.

HOSTING INSTITUTION AND PI INFO
| Name of Host Organization | NOVA Information Management School (NOVA IMS), Universidade Nova de Lisboa |
| Department or Lab | MagIC (Information Management Research Center) – the NOVA Information Management School research and development center |
| Name of Building | Manuel Vilares Building |
| Physical Address | Campus de Campolide, 1070-312 Lisboa |
| Website Links | https://www.novaims.unl.pt/ |
| Institutional contact name | Cristina Oliveira |
| Institutional contact email | magic@novaims.unl.pt |

APPLICATION CASES
| Application case: | Short description: |
| Predictive Maintenance in Manufacturing | Train and deploy machine learning models on sensor and operational data to predict equipment failures before they occur, reducing unplanned downtime, maintenance costs, and workplace safety risks in industrial environments. |
| Customer Churn Prediction | Develop classification models to identify customers at high risk of churning, enabling businesses to proactively deploy targeted retention strategies and improve customer lifetime value. |
| Credit Risk Scoring and Financial Fraud Detection | Build gradient boosting and ensemble models for credit risk assessment and real-time fraud detection, leveraging structured transaction data to support safer and more equitable financial decision-making. |
| Healthcare Outcome Prediction | Apply supervised machine learning to clinical and administrative healthcare data to predict patient readmission risks, disease progression, and treatment outcomes, supporting evidence-based clinical decision-making. |
| AutoML Pipeline Development and Benchmarking | Use MLLAB infrastructure to systematically benchmark AutoML frameworks across diverse datasets and problem types, supporting research into automated AI democratization tools for non-expert users and resource-constrained organizations. |

POTENTIAL STAKEHOLDERS
Non-academic stakeholders
Industrial Partners, Startups, Professional Associations, SMEs, Government Bodies, Other (Public agencies and municipalities)
Academic stakeholders
PhD students, MSc students, Researchers, Other (Visiting researchers, Seconded researchers)
Other types of stakeholders
R&I support professionals, R&I infrastructure operators, Innovation intermediaries, Technology transfer actors